
Github Vllm Project Vllm A High Throughput And Memory Efficient Github Vllm Project Vllm A High Throughput And Memory Efficient - Biography & Analysis
Ready to become a certified watsonx AI Assistant Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... Ready to serve your large language models faster, more vLLMs Labs for FREE — Most people can use an LLM. Very few know how to serve one at scale. In this video I demo a new but exciting feature: Custom LLM Serving on Databricks Model Serving EPs powered by In this video, we walk through the core architecture of We explored how to build and contribute to
Accelerating Open-Source RL and Agentic Inference with Everyone is racing to build smarter AI models. But once real users arrive, the biggest problem is not always the model — it is how ...
Curious about Github Vllm Project Vllm A High Throughput And Memory Efficient Github Vllm Project Vllm A High Throughput And Memory Efficient's Details? Explore detailed estimates, latest updates, and comprehensive information that reveal the full picture of their profile.
Visual Gallery






![End-To-End LLM DevOps Project w/ Docker, Kubernetes, vLLM [Step-by-Step Guide]](https://i.ytimg.com/vi/cm2tZm8lGSg/mqdefault.jpg)



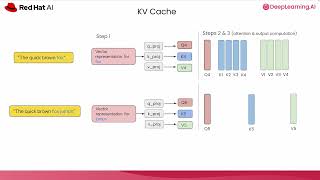
![[vLLM Office Hours #35] How to Build and Contribute to vLLM - October 23, 2025](https://i.ytimg.com/vi/RjTuvQwobbg/mqdefault.jpg)
information
Frequently Asked Questions
What is Github Vllm Project Vllm A High Throughput And Memory Efficient Github Vllm Project Vllm A High Throughput And Memory Efficient's estimated ?
As of 2026, Github Vllm Project Vllm A High Throughput And Memory Efficient Github Vllm Project Vllm A High Throughput And Memory Efficient's estimated is around $16M - $56M, based on extensive analysis of public records and media sources.
Where can I find latest updates for Github Vllm Project Vllm A High Throughput And Memory Efficient Github Vllm Project Vllm A High Throughput And Memory Efficient?
You can find the latest wealth reports, exclusive data updates, and private media insights for Github Vllm Project Vllm A High Throughput And Memory Efficient Github Vllm Project Vllm A High Throughput And Memory Efficient right here on our comprehensive profile hub.
